Variables Overview
Description
In the "Variables" section, all variables of the study are shown in one list, categorized by type. The most important variable properties (Name, Scale, Data Type, Data Format, Is Recorded, is Reset) are displayed. Each variable can be selected such that the variable's properties are shown and can be edited on the right side of the screen. Reviewing / inspecting all variable properties is recommended before publishing the study and starting the data recordings (e.g. check whether all relevant variables are being recorded, etc).
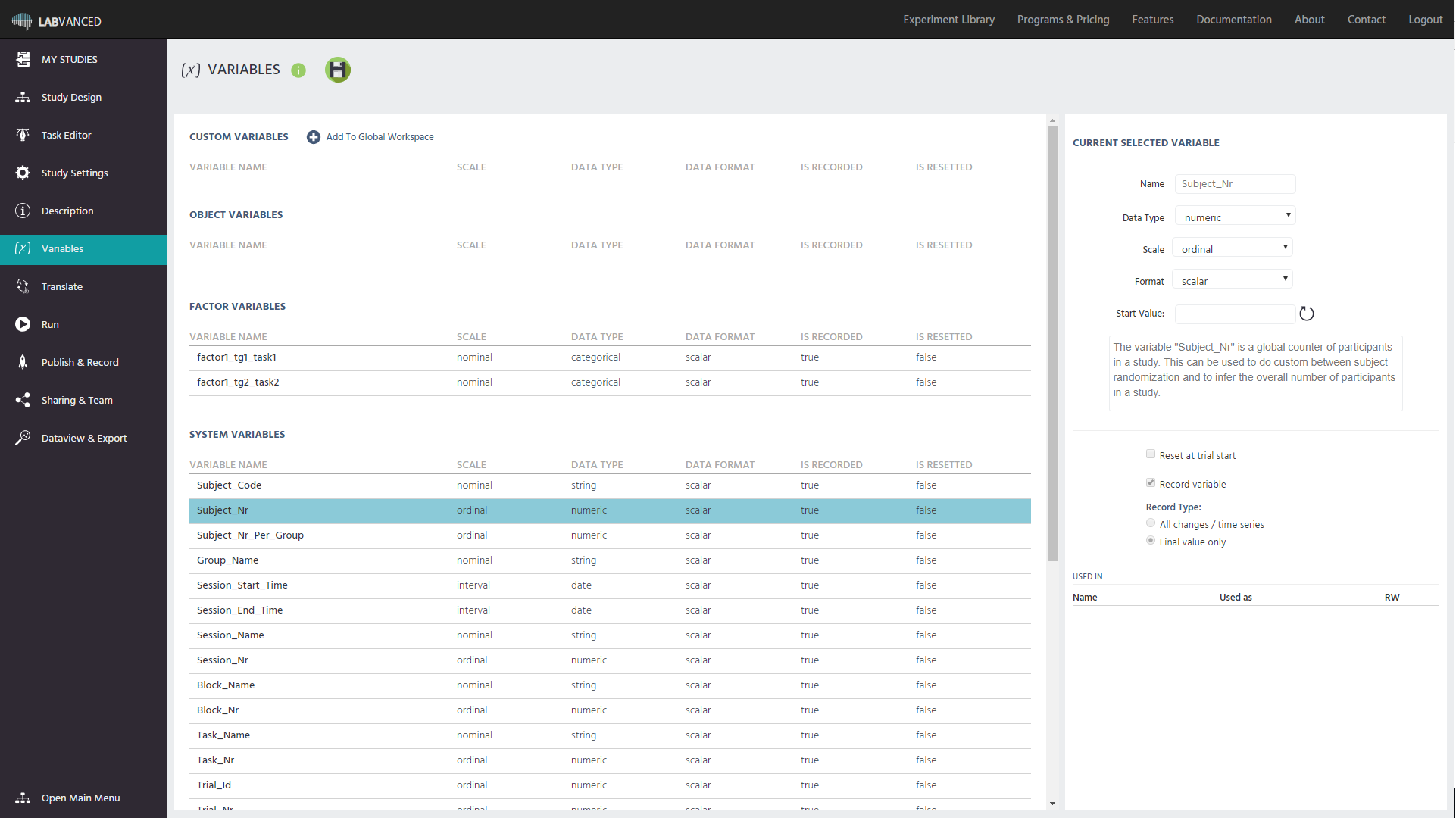
Variable Types
In the Variables overview, the variables are divided by their main type. There are 4 main variable types:
- Custom Variables: All of the user created variables.
- Object Variables: All variables that were created together with a (questionnaire) object (e.g checkbox, slider etc.)
- Factor Variables: All variables that function as factors within trial groups.
- System Variables: All automatically created variables (pre-created by Labvanced).
Variables are also categorized by their scope:
- Trial Variables: These are variables that are recorded per trial. Typically user-created, some examples include reaction times and participant choices.
- Session Variables: These variables are only recorded once per session and are mostly Labvanced-created. Some examples include browser type, screen size, and start/end times of the study.
- Subject Variables: These variables are only recorded once per subject and are Labvanced-created. These variables remain the same for the same subject across multiple sessions and include values such as subject ID.
Researchers will typically only look at trial and session variables. Subject variables are useful for longitudinal studies.
Deleting Variables
Deleting variables should be done with extreme care. Before deleting a variable, make sure that this variable is not used anywhere in your study. The variable usages are shown in the variable properties of the currently selected variable on the lower right portion of the screen (you may need to scroll down). While Labvanced tries to update these variable usages, please also check by looking into the different tasks and frames to see whether a variable is really unused or not before deleting it.
If you are not 100% sure that a variable is not being used, it is recommended to disable the recording of the variable. This way, the variable will not appear in the dataview, but there is no risk of damage to your study. Another option is to make a copy of your study (copy all variables and objects, etc.), then delete the variable in question from the COPY of the study and perform a test run. This way, you can see how the study will perform without that variable.
IF A VARIABLE THAT IS STILL USED SOMEWHERE IS DELETED (E.G. IN EVENTS OR OBJECTS) THIS MAY CAUSE IRREVERSIBLE DAMAGE TO YOUR STUDY! Please be careful!
Shared Variables
Shared variables are dynamic variables that can be shared across sessions and/or subjects. The variables are stored on the Labvanced server.
Between-Subjects Balancing
Imagine a study that has 10,000 images, but only 100 images are shown to each participant. However, each of the ten thousand images should be shown at least once, in a random order. Therefore 100 participants are needed to complete the study.
Shared variables can be used to write to an array that stores the numbers of the images that have not been shown yet. This ensures that Participant 2 does not see any of the images that Participant 1 saw. This balances stimuli between subjects on a stimulus basis. To prevent imbalance from drop-out participants, the variable can be set to only record an image as having been seen after the participant makes their response. This ensures a usable response for each image, regardless of whether a participant finished the study or not. Therefore, a study will result in randomized, balanced, and complete data.
Multi-Session (Longitudinal) Studies
Shared variables can be used to ensure that the subject uses (or does not use) the same device for each session of a longitudinal study.
In this case, another version of shared variables can be used. In this method, the shared variables are stored locally on the participant’s device and only shared with the participant themselves across sessions. However, this will not work if the subject uses a private browser or has a corrupted device.
In another example, imagine a study that has two sessions per participant. In each session, 100 images will be shown, but they will be entirely different between the two sessions. The images are picked randomly from a corpus of 10,000 images. You can draw numbers randomly and save them to an array for each subject to pick the images, then retrieve that array in the next session to make sure they are not picked a second time.
Multi-User Studies
These variables are used in studies involving multiple participants to send values from one person to another. This method uses server storage to distribute variables across subjects.
Remember the example above of a study that has 10,000 images, but only 100 images are shown to each participant. Each of the ten thousand images should be shown at least once, in a random order.
Again, shared variables can be used to write to an array that stores the numbers of the images that have not been shown yet. For this example, random numbers should be drawn at the initialization of the study and written to an array. The array will then include the images seen by each of the participants in the multi-user study. This ensures that Participant 2 does not see the same images that Participant 1 is currently seeing.
Sample Study
Imagine a sample study in which your intelligence is compared to that of a population in which the average intelligence is 100 points. Your score is only relevant when compared to others as a relative value. To make this comparison, the researcher could perform a post-hoc analysis, or they could give the participant live feedback.
Using shared variables, a participant’s score can be pushed to an array full of values. The array can then be averaged and the percentile value pushed back to the participant at the end of the study. In this way, the shared variable is updated dynamically as more individuals participate in the study, but the analysis is done during the study instead of post-hoc.